Title here
Summary here
December 15, 2021 in Data Platforms9 minutes

Cut through the clutter of the ETL tool market with our insights, helping you select the perfect tool for your data stack in the ever-evolving data landscape.
In this blog, we break down the paradox of choice to help you pick the right ETL tool! If you have seen the 2021 MAD (Machine Learning, AI & Data) chart by Matt Turks, there are countless tools already available and growing furiously. But how do you choose the best ETL tool that works for you? Here is the ultimate guide.
Let’s reflect on the past for a moment before we see the current & future of these ETL/ELT tools. Around the 2000s, hardly any organization realized a need for such tools. Most developers would write pages of TSQL or Perl or SAS programs. When they realized that this was becoming unmanageable, they turned to ETL tools such as IBM Information Server (Datastage & Quality Stage), SSIS, Informatica, or ABINITIO. That’s it. Most orgs had just one of them, maybe a few had more than one. All these tools have one purpose, moving and transforming the data.
The purpose of ETL/ELT has not changed for decades i.e. “Moving and transforming data”. What has continually changed and evolved are the type(s) of data, data sources, data targets and the way data move. Unfortunately, those traditional behemoths such as IBM or Informatica are not evolving fast enough to catch up. That is where these newcomers have filled the gap and have flooded the market. All this in less than a decade’s time.
 Matt Turk’s Machine Learning, AI and Data (MAD) Landscape
Matt Turk’s Machine Learning, AI and Data (MAD) Landscape
Has the purpose changed? NO. So why do we have 100(s) of ETL tools today? How to choose the best ETL tool for your modern data stack? Am I going to miss something if I don’t use a particular tool? It’s time to deep dive.
A summary of what will be discussed today:
Here are some of the common trends amongst the players in the marketplace today:
Many companies start with an open-source project, then commercialize the product. Talend started as an OSS project, that still offers a free version of their tool, but caters enterprises with cloud and enterprise versions. The trend is to start or pick an open-source project, add support, and offer them as a managed service. Databricks, Elastic Search, Airbyte and 100s of other companies fall under that category. They offer SaaS or PaaS without the hassle of having to manage those software packages.
Other small players identify a niche and build their product around it to fill that specific gap. Streamsets for example, is good at streaming small volumes, processing Change Data Captures events. dbt, is specialized in transformation, and does not offer E (extract) or L (load) or FiveTran, which offers only data ingestion. Another example is Xplenty and HighTouch which market their product as “Reverse ETL”.
This category annoys me the most. Many tools such as Astronomer aka Apache Airflow and Prefect upsell their products as ETL tool. No, they are not ETL tools rather, they are meant for orchestration. Atlas Mongo DB sells themselves as a search db as well as a data lake now, oh please! SingleStore Database, I still couldn’t wrap my head on what it is specialized for. They claim it can be used for anything from microservices to analytics.
Another common pitfall is pricing. Each provider comes up with their own terminology for pricing such as credits, units etc. Some products offer pricing based on the number of sources or targets. While others offer based on number of records processed.
Databricks introduced integration partners and it included dtb, fiveTran, Tableau and a lot other ETL/ELT tool. Yet they advertise their tool as “All your data, analytics and AI on one platform”. So why do we need the other tools then?
If you are an Enterprise Architect or Leader for a small-scale company or a large enterprise, it’s important to understand your current and future eco-system. This includes the technologies, databases, cloud service providers, resource skillset and roadmap.
This is a labelling exercise, where we tag the application/technology/platform with the domain. E.g. BigQuery & Snowflake as Warehousing, SalesForce as CRM, DB2z as Legacy CRM etc. Aggregate the no of data sources and estimated volumes for each domain.
This might seem like a painful exercise, especially for large enterprises, however if you are in the market for an ELT/ETL tool, this will be super helpful to make decisions.
There is no one size fits all solutions in the new world. You might end up having more than one toolset. At the same time, you don’t need tons of tools to do the job. Your modern ETL/ELT tools should be able to do the following:
The list above is a general guide; however, your organizational requirements may need more, feel free to expand that list.
If your organization has a guiding principle and a mature enterprise architecture, it is easy, however, many organizations don’t. Guiding Principles state the guard rails by which your application, choice of technology or reference architecture should align. For e.g.: A guiding principle might state that applications should be based on microservices architecture, or the technology should be open source, managed and located in the company CSP tenant. That is a topic by itself.
If you don’t have such principles, here are some tips:
At some point, you need to settle down on a toolset that works for you. One way to validate is answering these questions:
I should come up with a tool kit for evaluating softwares. But for today, I would like to wind down with a couple of architectural rules from “Fundamentals of Software Architecture”.
There are no bad decisions, only expensive ones.
-Fundamentals of Software Architecture
Another interesting rule to remember is:
Your goal should be to make a less wrong decision, not a perfect decision. Any decision made today will most likely become wrong in future.
-Fundamentals of Software Architecture
Adding a technology stack is one thing, encouraging your team/org to adapt to it is another. Upskilling is key to your success. A lot of these tools can do so many wonders unless you know how to use them.
Upskilling and digital dexterity will outweigh tenure and experience.
If you are transforming your traditional data engineers to cloud, here is an article on How to become a Cloud Data Engineer? .
If you are expecting me to suggest or recommend a tool in this post, sorry to disappoint you. My goal was to lay the foundation for choosing the right ETL tool, not necessarily make that decision for you. If your organization is looking for a citizen integration, and if I suggest Apache Spark or Databricks, then that would be a blunder.
But I would like to give you some examples in each cloud eco-system.
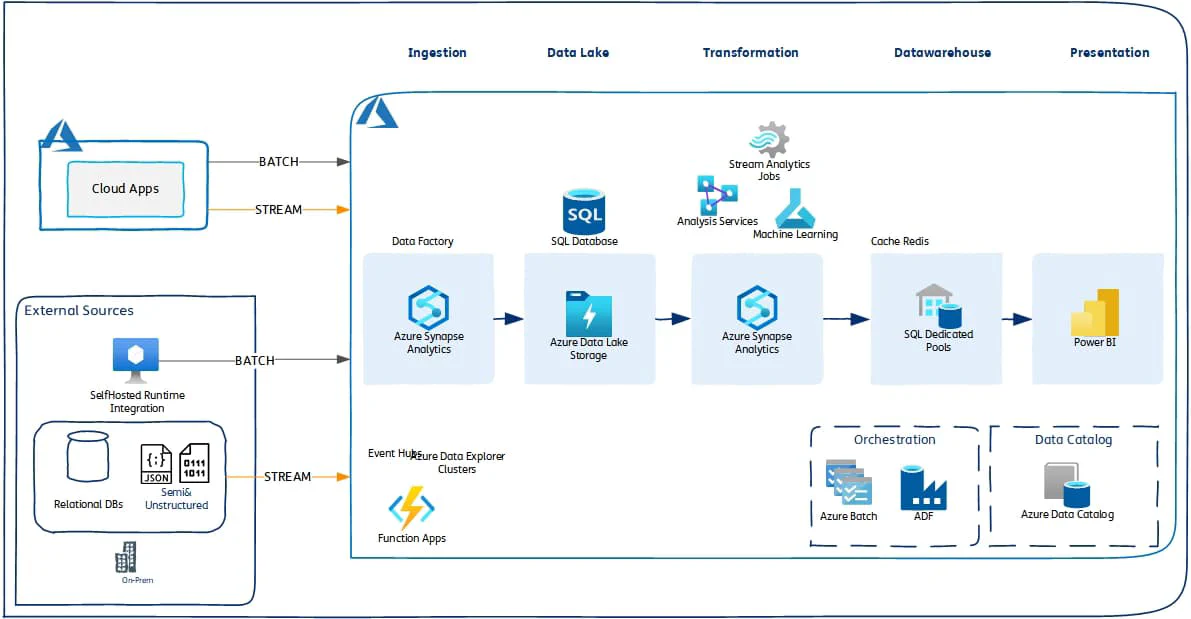 Azure Data Engineering Stack- Batch/Streaming ELT/ETL – Azure Data Factory
Azure Data Engineering Stack- Batch/Streaming ELT/ETL – Azure Data Factory
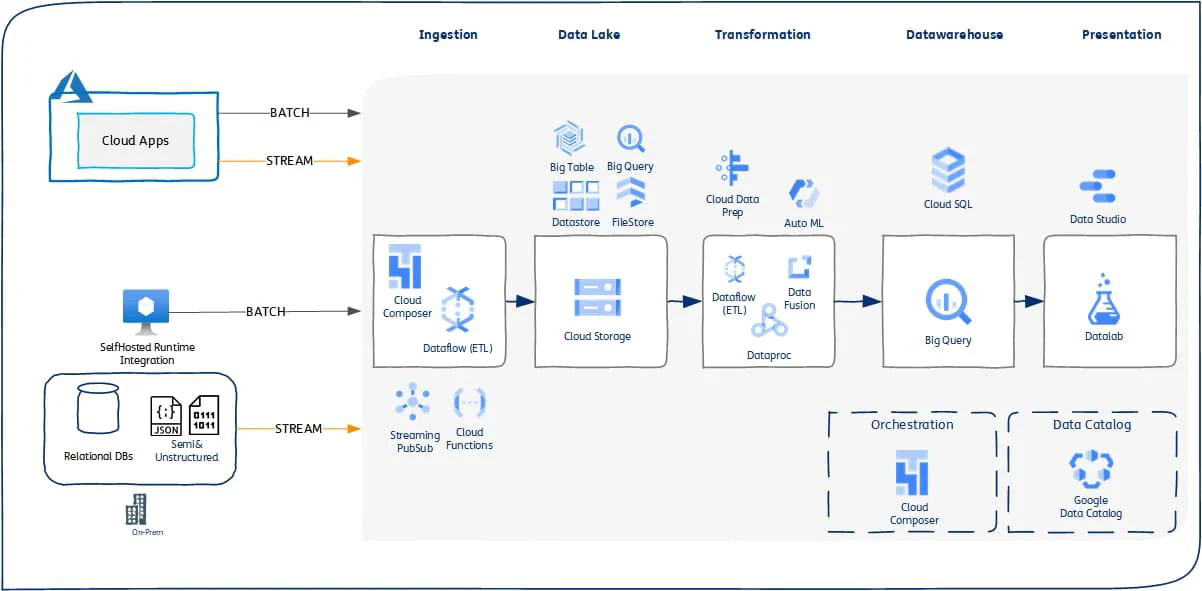 Google Cloud Platform (GCP) Data Engineering Stack- Batch ELT Data FLow (Managed Apache Beam)
Google Cloud Platform (GCP) Data Engineering Stack- Batch ELT Data FLow (Managed Apache Beam)
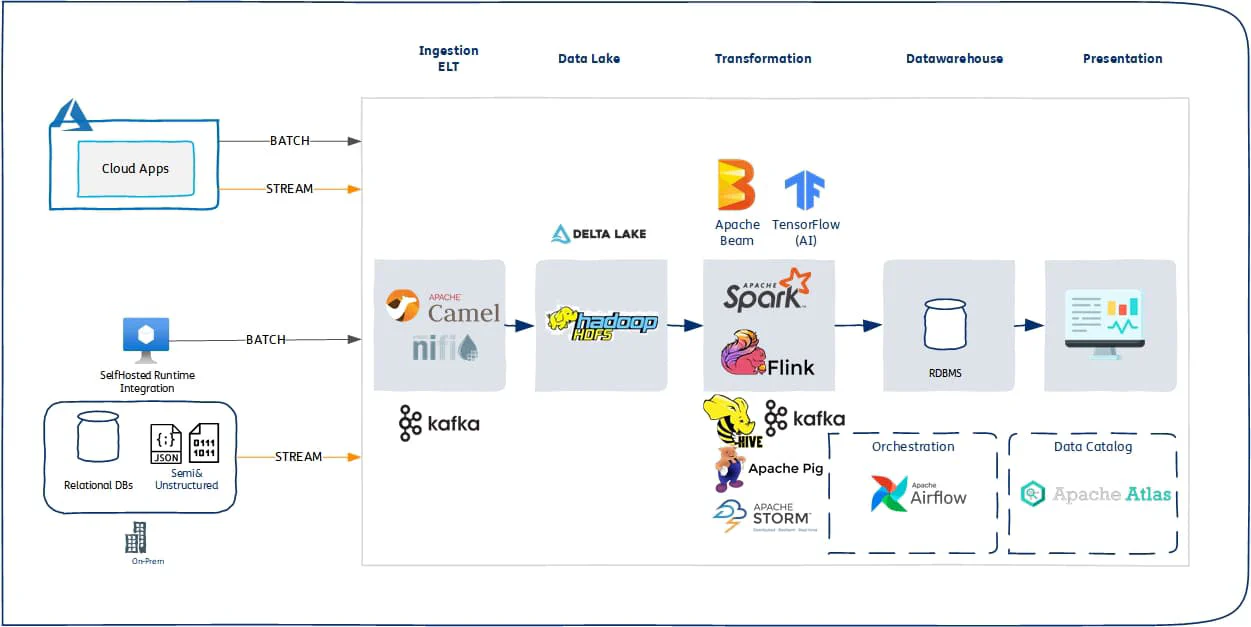 Open Source Data Engineering Stack- Batch ELT Data FLow (Apache Camel, NiFi)
Open Source Data Engineering Stack- Batch ELT Data FLow (Apache Camel, NiFi)
Would you like to contact me for ideas, questions or for collaboration?
I am passionate about data and have been working with and exploring tools for over 16 years now. Data technologies amazes me, and I continue learning every day. Happy to help!