Title here
Summary here
January 15, 2022 in Data Platforms12 minutes
Discover the path to becoming a Cloud Data Engineer with our step-by-step guide, enriched with professional insights and seasoned with sarcasm and humor.
Before I go too deep into this topic, let me share a little bit about myself. I am a Enterprise Cloud Architect for Data Platforms with over 14 years of experience in data engineering. Early in my career, I was an ETL Developer, but quickly became fascinated with data engineering. My cloud journey started with Google Cloud Platform in 2017 and there was no turning back since. So let me be blunt, if you are an UX UI developer or a system/database administrator or an application developer and want to become a data engineer in a brief period say 100 days, aint gonna happen! This post is specifically for folks who have exposure to Data/ETL/ELT/ESB platforms on legacy applications and are eager to move to cloud. I see many candidates clearing a bunch of cloud certifications and call themselves data engineers. However, data is one of the most complex pieces of any organization. Let’s say you are parsing a STRING “Hello World!” There are many questions you need to answer to parse the string correctly.
Most important thing is that you should know to ask these questions. These are not taught to you in any data engineering course. We learn it from experience and even then, many seasoned data engineers are not exposed to such complex scenarios. I am not discouraging folks with non-data engineering background from becoming a cloud data engineer, instead you might need more than 100 days, maybe a few years to get there. With that context let’s jump right in. Before we talk about Cloud Data Engineering, lets understand Cloud Architecture. ## Cloud Architecture
Cloud architecture is one of those buzz words we often hear these days. Cloud architect is really a systems architect who identifies the right infrastructure for an application. But the difference ends there, imagine owning a car vs riding on an uber? You put the capital on that car, pay the loan over the years, pay for maintenance, store it in a garage and so on. On the other hand, you click a few buttons and boom you have a car waiting for you. You don’t own a car or pay for its maintenance. Uber is not cheap, it’s more expensive than owning a car eventually. And so is Cloud! If that’s the case, why do companies move to the cloud? Just like Uber, cloud provides some unique opportunity - To use resources only when needed.
Perhaps, that’s a separate topic on its own, we shall focus on data engineering for now. IBM was a leader in data engineering (they are still a leader per Gartner, but I don’t believe in IBM anymore). They offered some powerful tools like IBM MQ, IBM Integration Bus, (IIB), IBM Information Server and more that can process massive data volumes. As data got complex, there was a need for more robust technologies that adapt to changing times. A centralized team building ETL, ELT or Message Integration flows will become a bottleneck for organizations. Not to mention the fact that IBM and similar companies failed to innovate in the changing landscape. ## Why Cloud Data Engineering?
Let’s start with the why. The need for processing data on the cloud became a crucial part of business units because the scale of data needs to be stored and analyzed. The growth of Internet users from 1991 (2.8 Million) to 2019 ( 3.7 Trillion) has contributed to this significant rise in data volumes. Cloud platforms can provide a near infinite storage, something that even large organizations cannot afford. Compare it to renting a storage unit for $100 per month vs buying land, building a storage unit, and securing it for $300,000. Another reason is data landscape is even more complex. Data is no longer just csv files, relation databases and queues. So how do you move to cloud? Cloud is a mindset shift. ## What is Cloud Data Engineering?
Often, we see role conflicts especially in the data space, analyst vs architect vs data scientists. Let’s clear that up. Some of the most common roles and responsibilities of a data engineer include: - Developing, constructing data lakes, databases, and data structures.
Organizations no longer stick to a single cloud provider. Is your organization stuck with a single cloud platform? If yes, it’s a poor strategy. Topic for another day. Here is how your roadmap to cloud data engineering should look like ### Prerequisites
Choose one among the top 3 cloud providers Azure, GCP or AWS (my least favorite). All the 3 cloud provides have free fundamentals class that not only covers their respective cloud services but also cloud in general. Research what your organization uses or moving towards. If you have plans to move soon, research what your potential employer uses. An example, if you are in retail then be aware that many retailers (not all) tend to avoid AWS ( you probably know why!). ### Step 2: Time Required <1 day
Sign up for their public cloud platform. You are not going to pay anything yet, so don’t worry much about giving your credit card number. These are the links for Azure and GCP. - Create Your Azure Free Account Today | Microsoft Azure
As you do it, bookmark these links. These are “always free” services that you run on the cloud. If you don’t want to burn your pocket, refer to the free-tier before creating resources. More on that later. - Free Services | Microsoft Azure
Start with the fundamentals class. I know you are in a rush; I can feel your adrenaline to pace directly to data engineering but be patient. Cloud is more than what you think you can handle. Understanding the fundamentals is necessary before you can dive deep. I wouldn’t recommend any additional courses other that what Microsoft and GCP Offers. #### Azure Fundamentals
By the time you move to step 4, you have a baseline, some basic hands-on on the GCP or Azure portal. You are now familiar with some terminologies like google storage bucket, Azure Blob Storage. In this step we will laser focus on ETL/ELT Tools. To be more specific you need to identify 4 tools and get yourself well acquainted with those tools. This will be your everything for your path to Cloud Data Engineering. 1. Batch Processing 2. Event Processing (Streaming) 3. Data Engineering Platform 4. Orchestration
Fair warning – dont get carried away with terms like Kubernetes, containers, Virtual Networks, Dev-ops etc. They have nothing to do with data engineering. While those are buzz words, don’t fall for it. They come under cloud infrastructure engineering. Here is some guidance though #### Azure Data Engineering Stack
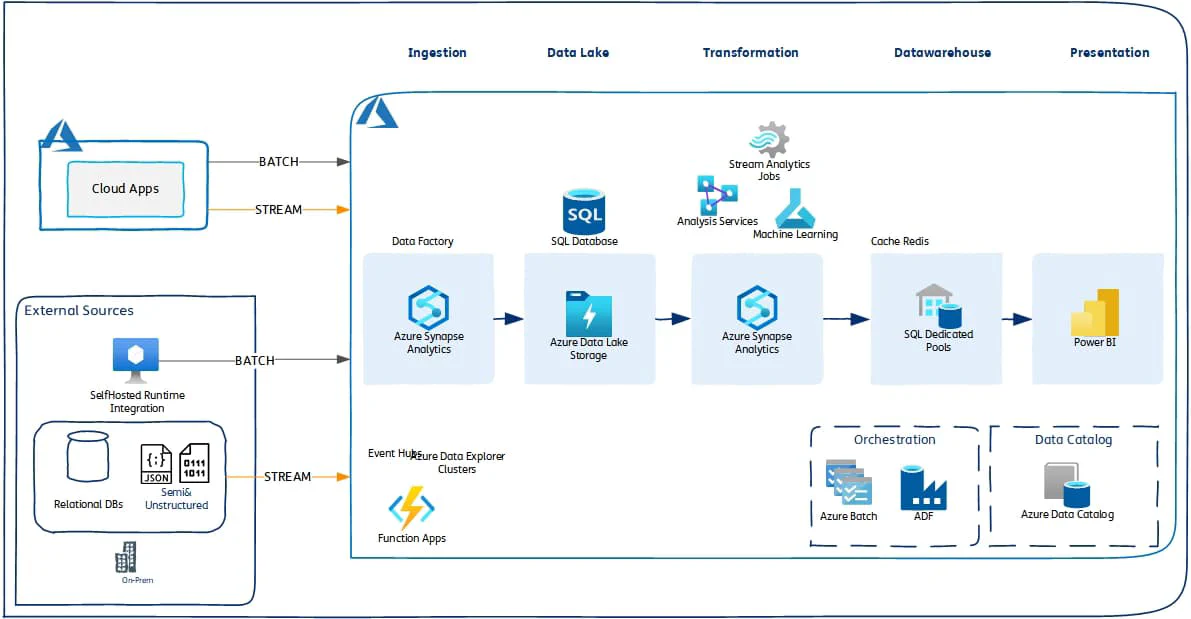 - Batch/Streaming ELT/ETL – Azure Data Factory
- Batch/Streaming ELT/ETL – Azure Data Factory
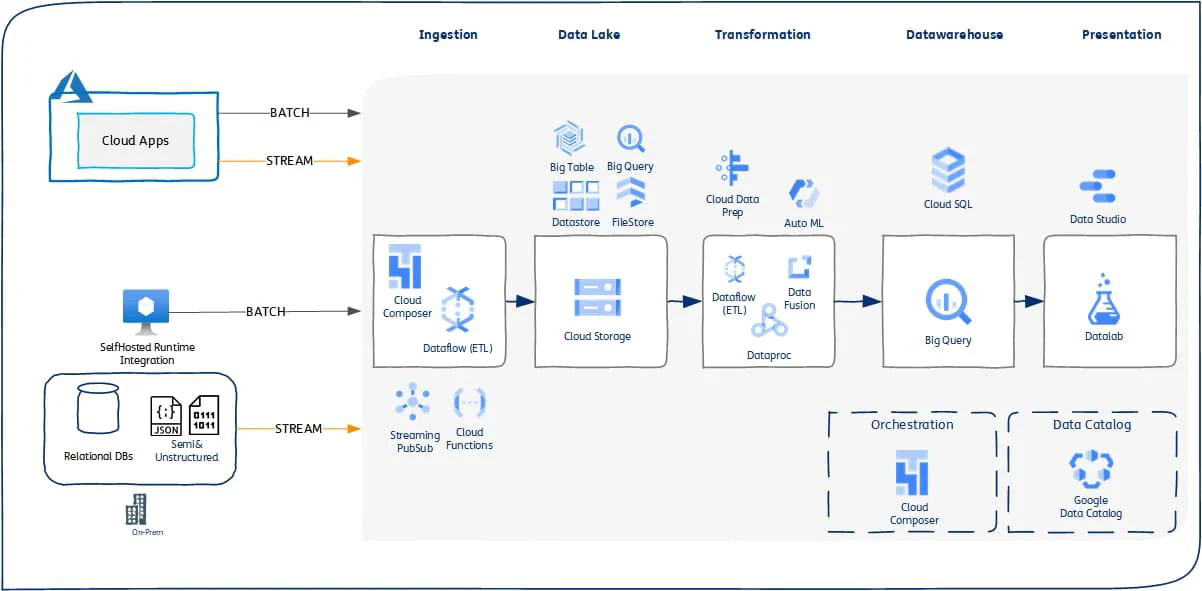 - Batch ELT Data FLow (Managed Apache Beam)
- Batch ELT Data FLow (Managed Apache Beam)
It’s time to get your hands dirty. You now know cloud basics, have decided the tools and have a feel of what Cloud Data Engineering looks like. Learn and play with these tools till you are comfortable. To be more specific, think of a data engineering project, and implement it end to end. Be creative with your ideas, one example is, get all the flight and airport data from online datasets and loading into your bigdata platform. Here is the source data for Flights and Airports from Kaggle. Its time to refer to the free-tier in step one. You can create certain resources for free. If you carefully choose and plan what you are doing you will hardly get billed. I get a bill of about $10-20 some training weeks might end up with $90. You might wonder what the best way is to learn, should I take any course in coursera, or pluralsights? I can tell you this much, it depends. I find it extremely hard to learn from videos, I prefer to read from the original cloud provider documents. But that’s me, I read books and am used to it. Microsoft Learn and Google Qwiklabs are valuable resources. Please refrain from YouTube videos unless they’re from the original Cloud Provider like Microsoft or Google. While many of those videos are attractive and useful, each of those youtubers has their own style and choices of tools that won’t resonate with what you have decided. Some of them are affiliated and so, they might have a biased opinion. You are not ready to think on your own yet, you are still in infancy with cloud. So better learn from the cloud providers. Here are some learning materials for Azure and GCP #### Courses for Data Engineering
Cloud technologies are changing rapidly. We get to hear new buzz words every day. So how do you keep up with that? Social media is a great place but not so great. I have tried to restrict my social media feed to my liking and so far, LinkedIn and twitter has failed me. But I have some tips. Cloud provides deploy influencers to share their products, its features and also keep their followers up to date on those areas they cover. Google calls them “Google Developer Advocates” and Microsoft calls them ” Microsoft MVP (Microsoft most valuable professional)”. They often share good, authentic content. So, feel free to follow them on twitter. Keep in mind that they are biased with certain products and specific cloud offerings. You should make the judgement call for your design/architecture. For starters you can follow - Google Cloud Tech (@GoogleCloudTech) / Twitter for how-tos, demos, product news, and more.
As I mentioned earlier, cloud is a mindset shift. In your traditional ETL practice, you were focused on data structures, data formats source and target systems such as SAP, Oracle, DB2Z etc. In Cloud ETL you will additionally focus on “services” and “cost”. Services – These are cloud native applications your ETL integrations will interact with. These range from Cloud Storage, Pub/Sub, Streaming Events, Cloud Tables etc. Cost – Remember the analogy of renting an uber? Traditionally you would be paying a premium for the license and install those on your company’s data center. Well now, you pay for the software, CPU, storage, backup, and DR features. What does that mean to you? You think about cost during development. - - - - - -
Let me walk you through an analogy – You have an on-perm Oracle OLTP database. There is an existing nightly batch process (probably some ETL job) that replicates the entire DB, syncs up EDW for metrics and reports. Imagine, OLTP system stays on-perm and EDW is moving to Google Big Query. How would you design it? You should stream Oracle CDC changes into Google Pub/Sub in real time and land those into a Datalake using Data Flow, eventually using Databricks to cleanse and model the data into Google Bigquery. Replicating the whole DB is no longer an option unless you want to bankrupt your organization. Azure and GCP has good price estimation tools. Make them your friend. - - - - - -
Lastly, it’s not fair if we don’t talk about open source. So, if you were to do data engineering with open source here is how it would look like.
While it’s good to know about this architecture, open source is not for everyone. It’s for companies whose core products are tech. Go back to “why” orgs are leveraging cloud? to reduce administration hurdles. Open source does the exact opposite, it adds a lot of administration overhead. The balanced act is finding a managed open source like Google Dataflow which is a managed Apache Beam or Databricks which is a managed Apache spark environment. Most companies that go for hybrid cloud seek such managed open-source products to avoid vendor lock-in. I am torn by that approach. Using Azure Data Factory is much better than using any other ETL tool for Azure so why would you pay for another tool? ##### Have more questions? I am happy to help you, feel free to reach out to hello@siva.blog.